转 Flink读取Kafka数据Sink到MySQL和HBase数据库
2020-01-14 17:44:16
5429 | 0 | 0
Flink将流数据Sink到数据库,一般需要自己自定义Sink的实现。下面示例,演示Sink到MySQL和HBase示例。
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
object KafkaToSinkStreaming {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val p = new Properties()
p.setProperty("bootstrap.servers", "localhost:9092")
p.setProperty("group.id", "test")
val input = env.addSource(new FlinkKafkaConsumer010[String]("test", new SimpleStringSchema(), p))
// 自定义MysqlSink类,将数据Sink到mysql
val sink = new MysqlSink("jdbc:mysql://localhost:3306/test", "root", "root")
input.addSink(sink)
// 自定义HBaseSink类,将数据Sink到HBase
val hBaseSink = new HBaseSink("student", "info")
input.addSink(hBaseSink)
env.execute("KafkaToSinkStreaming")
}
}自定义MysqlSink类
import java.sql.{Connection, DriverManager}
import com.google.gson.Gson
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
class MysqlSink(url: String, user: String, pwd: String) extends RichSinkFunction[String] {
var conn: Connection = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
Class.forName("com.mysql.jdbc.Driver")
conn = DriverManager.getConnection(url, user, pwd)
conn.setAutoCommit(false)
}
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
val g = new Gson()
val s = g.fromJson(value, classOf[Student])
println(value)
val p = conn.prepareStatement("replace into student(name,age,sex,sid) values(?,?,?,?)")
p.setString(1, s.name)
p.setString(2, s.age.toString)
p.setString(3, s.sex)
p.setString(4, s.sid)
p.execute()
conn.commit()
}
override def close(): Unit = {
super.close()
conn.close()
}
}自定义HBaseSink类
import com.google.gson.Gson
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants, TableName}
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
class HBaseSink(tableName: String, family: String) extends RichSinkFunction[String] {
var conn: Connection = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
val conf = HBaseConfiguration.create()
conf.set(HConstants.ZOOKEEPER_QUORUM, "localhost")
conn = ConnectionFactory.createConnection(conf)
}
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
val g = new Gson()
val student = g.fromJson(value, classOf[Student])
println(value)
println(student)
val t: Table = conn.getTable(TableName.valueOf(tableName))
val put: Put = new Put(Bytes.toBytes(student.sid))
put.addColumn(Bytes.toBytes(family), Bytes.toBytes("name"), Bytes.toBytes(student.name))
put.addColumn(Bytes.toBytes(family), Bytes.toBytes("age"), Bytes.toBytes(student.age))
put.addColumn(Bytes.toBytes(family), Bytes.toBytes("sex"), Bytes.toBytes(student.sex))
t.put(put)
t.close()
}
override def close(): Unit = {
super.close()
conn.close()
}
}Student类
case class Student(name: String, age: Int, sex: String, sid: String)执行KafkaToSinkStreaming程序后,在kafka product端输入。
{"name":"zhangsan","age":"18","sex":"male","sid":"1001"}
{"name":"lisi","age":"20","sex":"male","sid":"1002"}
{"name":"laowang","age":"20","sex":"male","sid":"1003"}
{"name":"caocao","age":"28","sex":"male","sid":"1004"}mysql的数据库结果:

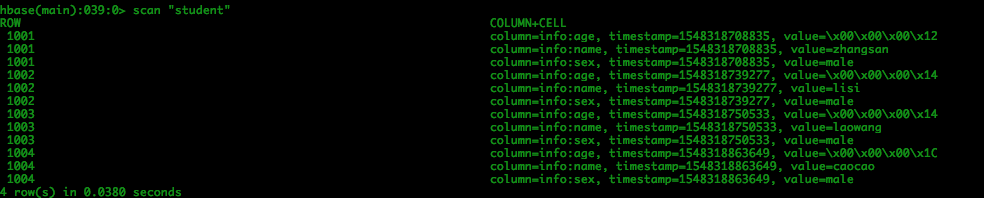
HBase数据库结果:
项目源码:https://github.com/zhang3550545/flinkdemo
相差阅读推荐:https://www.roncoo.com/view/171
0
收藏
分享

135****3683
14人已关注
关注
最新文章
-
 领课教育 33868
领课教育 33868 -
11490
- update 49128
-
5988
- 领课教育 19456
-
 husheng 21857
husheng 21857 -
 请更新代码 42689
请更新代码 42689 -
 凯哥Java 3249
凯哥Java 3249 - 凯哥Java 3764
- 凯哥Java 2964

 粤公网安备 44010602005928号
粤公网安备 44010602005928号